ANDREI BARBU: Então, queríamos
manter o tema de cérebros, mentes e máquinas,
e ter um tutorial que tenta orientá-lo desde não saber
nada sobre aprendizado de máquina até como você faz algumas
coisas muito básicas, como como os classificadores lineares
trabalho, qual é a intuição por trás das
redes convolucionais modernas. Quais são as limitações,
que é algo sobre o qual David estará falando. E, finalmente,
Colin falará sobre como o conhecimento
do cérebro, neste caso o
cérebro de ratos, pode ser usado
para talvez um dia melhorar o desempenho
de nossas redes e, definitivamente, tentar
entender o que está acontecendo dentro do cérebro. de ratos. Existem alguns links aqui. Vamos compartilhar os
slides e as diversas planilhas Colab que estamos usando. Mas não há necessidade de
acompanhar por enquanto. Portanto, a visão de máquina
é provavelmente uma das áreas mais populares da
IA atualmente e do aprendizado de máquina. E entre as muitas
tarefas diferentes em visão de máquina, a detecção de objetos
se destaca como – eles têm sido uma espécie de
tarefa principal em que as pessoas estão interessadas.
Mas isso geralmente se
reduz à tarefa de colocar
caixas delimitadoras em torno de objetos de diferentes categorias. Mas é claro que você ou eu temos um
conhecimento muito mais rico do mundo do que simplesmente
saber que existe uma caixa delimitadora em volta de
um cachorro ou de uma cadeira. Mas para o bem ou para o mal,
é assim que nós, como um campo, definimos a
detecção de objetos por enquanto.
E os detectores de objetos estão sendo
implantados no mundo real. Você pode atravessar a rua enquanto
um detector de objetos o observa. Esse detector de objetos
pode salvar sua vida. Hoje em dia, eles são
implantados em carros reais. E o carro pode parar porque
aquele detector de objetos detectou você. Claro, com as implantações
também vêm as falhas. Portanto, neste caso,
houve uma falha muito trágica de visão computacional há cerca de dois,
três anos na Tesla, onde alguém dirigia
um carro autônomo. E o detector de objetos
não detectou um caminhão branco em um céu azul
sem nuvens. E o carro simplesmente
bateu no caminhão. Você ou eu teríamos
visto, mas o motorista estava confiando no piloto automático
e não teve tempo de reação quando possivelmente
percebeu o caminhão para fazer algo a respeito. Portanto, a visão computacional
é extremamente útil, mas ainda possui algumas
limitações significativas em comparação com as habilidades que os
humanos ou até mesmo os animais têm quando se trata de ver
objetos em nosso ambiente.
E então eu queria
começar com os blocos de construção fundamentais mais básicos
do aprendizado de máquina e construir o
que está dentro de um desses modernos
detectores de objetos baseados em CNN. Todos eles, mais ou menos,
se parecem uns com os outros. E então David
lhe dirá quando as coisas falharem. E Colin vai compará-los
com cérebros de roedores. Portanto, no centro de tudo está
a classificação [INAUDÍVEL]. Você pode obter uma
coleção de pontos. Esses dois conjuntos de pontos
se agrupam muito bem. E uma máquina pode
ver todos os pontos sem saber quais rótulos
correspondem a quais pontos.
E um tempo de treino vai receber
um mapa bem claro como esse. E um tempo de teste
terá que decidir quais pontos se enquadram em qual cluster. E uma das
maneiras mais diretas de fazer isso, que é
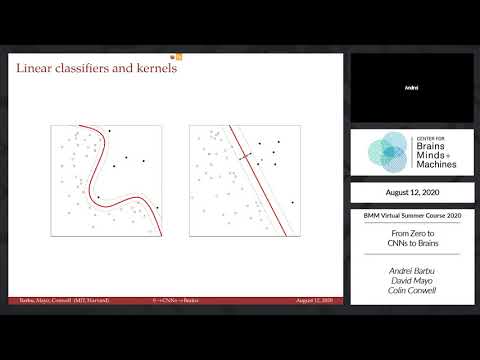
conhecida há muitas décadas, é a classificação linear. Em outras palavras, você
tentaria encontrar um limite de decisão linear , onde
você diz, tudo à esquerda da minha
linha é um círculo e tudo à direita
da minha linha é, neste caso, uma cruz. Claro que
nem sempre funciona. Nesse caso, esse não é um
limite de decisão muito bom, nem este.
Mas existem,
pelo menos para esses conjuntos de pontos, bons limites de decisão,
como esses dois. E alguns deles
que nós preferimos, se você apenas olhar para os dados,
parece que o vermelho é mais robusto do que
o outro tracejado que está no centro. O que vamos
fazer é transformar esse problema em algo que possamos
resolver no PyTorch e criar o
classificador linear para diferenciar esses pontos. Agora, é claro, os pontos vêm
a diferentes distâncias desta linha. Alguns pontos estarão
muito próximos a ele e outros muito distantes. Então você realmente gostaria
de ter apenas duas respostas. Estou do lado esquerdo da linha
ou do lado direito da linha? E uma maneira de fazer isso
é basicamente reduzir a distância entre a linha
e cada ponto com um sigmoide. Então, se você estiver
infinitamente longe da
linha da esquerda, a resposta será menos 1. E se você estiver infinitamente
longe da direita, a resposta será 1. E é exatamente disso que estamos
falando. para fazer em um momento.
Podemos pensar nisso como um
problema de otimização bidimensional. Em outras palavras, essa
linha central, ou qualquer linha, tem um deslocamento e
uma rotação. E quero encontrar o
deslocamento em rotação da minha linha que classifique meus
pontos corretamente. E se você tentar operacionalizar
a noção de classificar os pontos corretamente,
você pode medir, quantos pontos
no meu conjunto de treinamento estou classificando corretamente em
cada uma das duas categorias? E algumas combinações de deslocamentos
e orientações de sua linha farão um
trabalho ruim e classificarão incorretamente a grande maioria dos pontos. E outros vão
fazer um ótimo trabalho. E então você obtém essa
paisagem de energia onde você tem picos.
Nesse caso, os picos são ruins. E vales, onde
você tem boas respostas, e muitas vezes você tem
diferentes mínimos locais– em outras palavras, várias
respostas que funcionam bem. Em alguns casos, um pode
ser melhor que o outro, mas ambos podem ser
soluções aceitáveis. E o grande martelo que
temos para alinhar esses parâmetros
dessas linhas corretamente é chamado de gradiente descendente. E o que
ele faz é permitir que você olhe localmente para
a forma da paisagem logo abaixo de você. Então, se você imaginar
que está em um desses pontos desta colina
e olhar para os seus pés, não poderá ver a paisagem. Mas simplesmente olhando
para os seus pés, você pode ver que a colina
aponta para uma certa direção e que, se você der
um passo nessa direção, estará
descendo a colina.
Isso é tudo que a
descida do gradiente é. Ele permite que você calcule
o gradiente, ou seja, a inclinação daquela colina. Na verdade, damos
muitos pequenos passos. E isso
é o gradiente descendente. [INAUDÍVEL] falou sobre isso. Uma das coisas que você pode
fazer com esse tipo de configuração, no entanto, é separar pontos
que a princípio podem não parecer linearmente separáveis. Portanto, não há uma linha reta
separando os pontos pretos dos círculos abertos aqui. Mas se eu reprojetar esses
pontos em algum outro espaço várias vezes,
eventualmente, a esperança é que eu seja capaz de distorcer
o espaço o suficiente para encontrar uma linha reta
que os separe. Essa é a intuição
por trás de por que vamos acabar aplicando
múltiplas transformações aos nossos pontos e, eventualmente,
ter um classificador linear em cima de tudo que
tenta dividi-los em várias categorias.
Então, apenas para mostrar a você como
isso se parece no PyTorch, há– e novamente, vamos
compartilhar essas planilhas do Colab com você. Há algumas configurações preliminares básicas
que você precisa fazer, importando algumas bibliotecas básicas. Não vamos falar muito sobre isso. Acabei de inserir as
coordenadas dos pontos daquele slide anterior. E poderíamos apenas
mostrá-los em linha. Se você nunca usou o Colab antes,
ou Jupyter Notebooks, sobre o qual o Colab é construído
, esta é definitivamente uma ferramenta que vale a pena
brincar. É muito poderoso
ter gráficos embutidos para poder compartilhar notas e
ter seu código entrelaçado com sua configuração experimental. Então, para chegar ao cerne
do classificador linear, vamos fazer uma configuração,
um modelo muito simples. Este é provavelmente o modelo mais simples que
você pode configurar no PyTorch. E esta é uma camada linear
que recebe duas entradas e tem uma saída.
E as duas entradas são as
coordenadas x e y de cada ponto. E a única saída,
bem, queremos saber essencialmente a que
distância esse ponto está de nossa linha reta. Vamos ter um
critério, uma perda que define a forma
dessa paisagem que olhamos há pouco. Neste caso, vamos fazer
a perda de entropia cruzada binária. Tudo isso vai
medir quantos pontos estão sendo classificados erroneamente como
parte de uma classe em oposição à outra.
Portanto, o valor ideal
para isso será uma linha que
separe claramente os dois. Vamos
configurar algum otimizador. Neste caso, é uma
descida de gradiente estocástica. E teremos
alguma taxa de aprendizado. Para SGD, a
taxa de aprendizado corresponde ao tamanho do
passo que você deseja dar. E se você se lembra daquela imagem
com as colinas e os vales, bem, se seus passos
forem muito largos, você pode passar de um
vale para outra colina.
E, com muita frequência,
o que as pessoas farão é começar com
tamanhos de etapa grandes no início para sair de um lugar muito ruim
no cenário de otimização e, em seguida, reduzir lentamente a
taxa de aprendizado. E hoje em dia, temos
otimizadores muito mais poderosos que farão isso
por você, como Adam. Mas vamos nos ater
apenas à descida do gradiente estocástico aqui. Vamos apenas
escolher uma taxa de aprendizado. Também podemos plotar facilmente o
modelo atual que temos. Então eu inicializei esta camada. E sempre que você
inicializar um modelo, ele terá alguns
valores aleatórios dentro dele. E o PyTorch tenta
escolher distribuições de forma inteligente para
essas variáveis aleatórias. Você pode ver que esta
linha totalmente aleatória não é um bom classificador. Isso classifica metade dos pontos,
quase tão ruim quanto você pode obter. Mas podemos tentar ajustar o
slide e rodar nosso otimizador.
Tudo o que essas duas linhas fazem é
apenas remodelar nossos pontos para que sejam matrizes 1D. Portanto, apenas concatena
os dois pontos das duas classes . E criamos outro
array que tem os alvos, os
rótulos que queremos atribuir a esses pontos,
novamente, um array 1D, onde temos 0's para uma categoria
e 1 para a outra categoria. E se quisermos executar nosso
modelo, tudo o que precisamos fazer é passar as entradas para o modelo. Basta chamá-lo como
a função normal e obter suas saídas. Passe-o pelo sigmóide,
como dissemos há pouco, para não nos importarmos com a
distância até esta linha, apenas se estamos
à esquerda ou à direita. Coloque-o em seu
critério, que é, novamente, nossa perda de entropia cruzada binária. E dê ao critério
o rótulo verdadeiro para que saibamos que esta é a
previsão que estamos fazendo e este é o alvo.
E saberemos a que altura
estamos no cenário energético. Agora, tudo o que isso faz
é calcular onde estamos nesse cenário de energia. A outra coisa
que queremos saber é: como é a paisagem
sob uma pilha? Então, em que direção
devemos ir para descer a colina, em
vez de subir a colina ou permanecer no mesmo local? E é isso que as próximas
duas linhas estão fazendo. Por vários
motivos de otimização que não abordaremos, você precisa zerar algum
estado para seu otimizador. E então você chama a
função para trás. E o que essa
função retrógrada faz é — essa é realmente a
mágica do PyTorch, essa ferramenta chamada
diferenciação automática, que pega a função que
você executou, pega esse modelo — e por falar nisso, o
critério e o modelo combinados juntos — e, essencialmente, analisa-o
e propaga informações através dele,
a fim de descobrir qual é a forma da
paisagem local sob seus pés. A maneira mais fácil de
pensar sobre isso é que essa função pode
fazer diferenças finitas.
Em outras palavras, ele
poderia pegar seu modelo e alterar um pouco a entrada
em diferentes
direções aleatórias e ver como seria a colina
se você tivesse dado um pequeno passo para cima ou para baixo
na colina, para a esquerda ou para a direita. E com base nisso,
ele dirá em qual direção você deve seguir
para descer a ladeira. Na verdade não é isso que
acontece. O que acontece é que há um
pouco de cálculo envolvido. E há muitos recursos
para diferenciação automática online, então não vou
abordá-los aqui. Mas essa é a intuição básica. E então usamos a direção
que você calculou no seu otimizador, e você
desce a ladeira. Podemos executar este otimizador. Este modelo funciona
muito, muito rapidamente. Você pode ver que a perda
diminui, não muito rapidamente. Corremos apenas 100 passos. Mas você já pode ver que a
linha parece muito diferente. E já, alguns dos
pontos da esquerda fazem parte de uma classe, alguns
dos pontos da direita ou parte de outra classe. Pude ver que, se a
linha se movesse em direção ao meio,
estaríamos em muito boa forma aqui.
Também é muito bom poder
ver os parâmetros do seu modelo. Então, podemos realmente
investigar quais parâmetros nossa camada linear tem aqui. Neste caso, é
apenas uma pequena matriz na qual você alimenta um ponto 2D. Ele projeta isso ao
ponto, faz uma multiplicação entre isso e seu vetor. E então adiciona um viés,
adiciona esse valor a ele. Então é um pouco
de álgebra do ensino médio. Você pode pegar esses
valores e descobrir como reprojetar essa linha. Basicamente, você está
perguntando, qual é o limite de decisão que
corresponde ao meu modelo? E essa é uma das
visualizações mais populares para o que sua rede neural está fazendo.
Contanto que você não esteja
em muitas dimensões, encontre alguma
região 2D ou 3D interessante e volte e plote a
aparência do limite de decisão, que para uma
função linear parecerá, obviamente, como uma linha reta. Mas à medida que sua rede
se torna mais complicada, você obterá
o efeito que vimos nos slides, onde
seu limite de decisão de repente assumirá
algumas formas interessantes, formas fechadas, etc. E podemos até assistir a
essa otimização acontecer em tempo real.
Poderíamos executar a função. Ah, aparentemente o Colab resolveu
me desconectar no meio do caminho. Mas poderíamos executar a
função e observar essa linha se mover lentamente. E você pode brincar
com isso em casa se quiser experimentar
diferentes taxas de aprendizado e o que, de fato,
eles podem ter, bem como diferentes
tipos de inicializações. Isso apenas nos fala
sobre classificadores lineares. Isso é literalmente a coisa mais simples que
podemos fazer. Mas é claro que gostaríamos
de falar sobre detecção de objetos. E no coração
dos detectores de objetos modernos não está apenas
essa operação linear. Mas antes disso, é uma operação
chamada de convolução. E isso vem do
processamento de sinal, onde você tem um sinal. Neste caso, você poderia
imaginar como um sinal de áudio. E isso é amplitude. E eu tenho um filtro,
neste caso, um filtro de caixa. E lentamente deslizo meu
filtro ao longo do meu sinal e obtenho uma resposta do
filtro ao meu sinal. Podemos jogar o mesmo
jogo com imagens.
Neste caso, temos um
kernel, que é o filtro. Temos uma imagem de entrada e
uma imagem de saída. Pegamos o kernel,
deslizamos em cada posição na imagem de entrada. Em cada local,
multiplicamos o valor que está no kernel pelo
valor que está na imagem. E enviamos todos juntos. E isso produz um único
pixel na imagem de saída. Se você apenas repetir
isso, realizará muitas transformações de imagem interessantes
, incluindo a mais
popular que provavelmente existe em todas as ferramentas de processamento de imagem
do mundo, que é o desfoque. Se você quiser desfocar uma
imagem, a maneira de fazer isso é usar o que é
chamado de desfoque guassiano. Em outras palavras, você cria
um desses kernels que tem muita energia no meio. E a energia diminui à medida que
desce para os lados. É apenas uma matriz. Não há nada de
especial nisso. Mas uma maneira de
pensar sobre isso é que um desfoque envolve tirar
uma certa quantidade de informação do pixel central
e, em seguida, permitir que todos os outros pixels tenham
alguma influência. Isso é meio que
espalhar essa informação. E, de fato, você desfoca uma imagem
se convoluir o kernel Gaussiano [INAUDÍVEL] .
Mas você pode colocar o que
quiser nessas matrizes, nesses kernels. E voltando, novamente, 30,
40 anos, ainda mais, uma das operações mais básicas
que as pessoas descobriram é a transformada de Laplace. Esta é uma matriz 3 por 3
, ou um par de matrizes 3 por 3, que
têm valor 0 se forem aplicadas a uma imagem branca. Porque se os valores
à esquerda e os valores à direita forem
iguais, eles simplesmente se cancelarão quando
você os enviar juntos. Mas se houver mais
energia deste lado e menos energia deste
lado, ou vice-versa, isso não se anula. Você obterá uma alta
resposta para este kernel. Em outras palavras, este kernel
está procurando arestas verticais e este kernel está
procurando arestas horizontais. E é aí que eles
terão resposta máxima em qualquer região 3 por 3 de
uma imagem com a qual estão sendo convoluídos. E se tudo o que você fizer for
pegar sua imagem, você pode consolá-la com
o kernel à esquerda e o kernel à direita
e calcular a magnitude da resposta, porque
você acaba com duas imagens naquele ponto, o que você tem
é um detector de arestas de Sobel.
Você pega a imagem da
esquerda, executa aquela operação e obtém a imagem da direita. E você pode imaginar transformar
isso em um detector de borda. Ou você pode até imaginar transformá-
lo em um detector de objetos. Imagine por um segundo que você está
sentado em uma fábrica e precisa verificar se
essas peças à esquerda estão corretas e se apenas
ignoraram seu sensor. Bem, se você pegar
uma única parte boa, calcular este
mapa à direita, tudo o que você precisa fazer é
multiplicar cada imagem pelo mapa à direita. E sempre que a
multiplicação tiver um valor alto, sempre que
o produto escalar for alto, isso significa que
a imagem que você está vendo é muito parecida com a imagem
que você tinha antes. E quando isso não é verdade,
bem, talvez algo tenha dado errado com a sua parte.
Esse é provavelmente o
detector de objetos mais simples do mundo que você pode imaginar. Bem, as pessoas fizeram isso. Mas é claro que você
tem um problema, porque as peças podem se mover. Eles podem ser girados. Eles podem ter partes
ou subpartes. E então a próxima grande coisa
que as pessoas disseram é– bem, estou
pulando muito trabalho aqui, então esta é uma
história muito seletiva de detecção de objetos. Mas a próxima grande
novidade foi por volta dos anos 2000 , onde você pega aqueles
mapas de borda que viu antes, você os guarda. E cada caixa, em vez de
armazenar a borda em si, você apenas armazena as
estatísticas da caixa. Então você diz, como
é o histograma da orientação da
energia em diferentes direções ? E o que isso faz é
comprar uma certa quantidade de preguiça, porque se esta roda
for ligeiramente girada, não importa.
Agora não estou perguntando,
a borda da roda combina perfeitamente com a
borda do meu filtro? Tudo o que estou perguntando
é, nesta região onde está a borda da roda
, as estatísticas são semelhantes às do meu filtro? E as pessoas correram com essa ideia. Isso é chamado de
histograma de gradientes. Eles criaram o que é
chamado de detector de peças deformáveis , onde você apenas aplica
essa ideia repetidamente. Portanto, este é um
detector de peças deformáveis para humanos, onde você pode ver
que é uma espécie de cabeça.
Então você está dizendo que as
bordas ao redor da cabeça são orientadas
em forma de telhado. E há armas. E o rosto meio que tem
arestas por toda parte. E depois de
aplicar esse filtro e ter alguma confiança de
que pode ser uma pessoa, você pode aplicar
filtros ainda mais refinados. Então podemos ver agora, ao invés
de ter compartimentos realmente grandes para cada parte do ser humano,
temos compartimentos cada vez menores. E, claro, os humanos
são deformáveis. Então as pessoas disseram, bem, que
tal cortarmos o filtro em
pedaços, e permitirmos que o filtro se
mova, e perguntar, qual é o melhor local para a
cabeça filtrar para este humano? E eu não quero que a cabeça
fique abaixo dos pés, então vou colocar
um mapa de deformação que só permite que a cabeça se
mova um pouco.
E você tem um filtro para a
cabeça, os braços e as pernas. Este foi o estado da arte
na década de 2010 ou mais. Mas acontece que isso
já é uma espécie de rede profunda. Temos vários conjuntos de
filtros que estamos aplicando. Convolvemos uma imagem
com alguns filtros. E estamos fazendo,
essencialmente, um agrupamento máximo, onde
estamos perguntando onde os braços se encaixam melhor em uma imagem.
E assim, enquanto os
detectores de objetos modernos são um pouco mais inescrutáveis do que
os que os precederam, porque você só
tem esses diagramas métricos bastante complicados
e é difícil olhar para os
parâmetros que são aprendidos, em comparação com o quão
interpretáveis eles eram no passado, particularmente
à medida que as redes se aprofundam, a intuição é
exatamente a mesma.
Você tem uma imagem. Você tem convoluções que são
aplicadas a esta imagem, que são seus filtros. Você executa esse pooling máximo
em regiões onde diz, não me importa onde
esse filtro foi bem-sucedido. Eu só quero saber, qual
foi a sua resposta máxima? E você apenas repete isso
de novo e de novo e de novo. E esta é a
arquitetura do AlexNet.
Esta é a primeira
rede profunda popular que se saiu bem no ImageNet
e convenceu as pessoas a continuar pressionando
, e é a espinha dorsal de quase
todos os detectores de objetos modernos. Eles não parecem muito
diferentes em comparação com isso. E claro, no
final de tudo isso, temos aquela camada linear da qual
falei há pouco. Portanto, a história básica é que
você usa imagens como entrada. Você propõe algumas regiões que
provavelmente terão objetos. Você alimenta essa
imagem através de uma rede que tem muitas e muitas camadas. E você acaba com esse
classificador linear no topo, porque todas essas
camadas fizeram o que o kernel no
caso linear fez anteriormente, que é desemaranhar o espaço. E tornou as imagens
linearmente separáveis, ou a representação
das imagens.
E na planilha do Colab,
incluí um rápido passo a passo do AlexNet. Existem muitos tutoriais sobre ele. Vale a pena dar uma olhada. Mas uma vez que você brinca
com os classificadores lineares, é realmente apenas
mais do mesmo. E o PyTorch cuida
do trabalho pesado para você. E isso realmente fez uma grande
diferença no desempenho. Isso é desempenho no ImageNet. Desde 2014, ficou
muito, muito melhor. Mas, infelizmente, o
problema não está resolvido. E é sobre isso que David
falará a seguir. Se você alimentar imagens que
parecem diferentes do conjunto de treinamento, de modo que se pareçam com
as imagens que foram usadas para definir os parâmetros
dessa rede, da mesma forma que definimos os parâmetros
dessa função linear, elas podem
ficar muito confusas. Então, neste caso,
coloquei esta imagem por meio de um sistema de legendas de última geração
publicado no final de 2019.
E dizia, há um homem e
uma criança sentados em um avião, porque nunca vi imagens
de bebês tentando para dirigir carros. E deixarei que
David mostre a você como esse problema é ruim e que
soluções podem existir para ele. DAVID MAYO: OK,
então acho que Andrei deu uma ótima visão geral da introdução
aos modelos e introdução à visão.
E agora vamos
dar uma olhada mais de perto em como alguns desses
pontos de dados reais em seus gráficos se parecem. E eles assumem a forma de imagens
de vários conjuntos de dados de imagem. Assim como a história
do aprendizado de máquina, um componente importante foi
criar conjuntos de dados melhores. E grandes conjuntos de dados
nos permitiram ter grandes quantidades
de dados de treinamento e poder
criar modelos com bom desempenho na classificação. Então, aqui está um exemplo rápido no
PyTorch de como realmente carregamos muitos conjuntos de
dados de reconhecimento de objetos modernos em um Jupyter Notebook. Portanto, a primeira coisa que você
precisa fazer para carregar modelos é basicamente
criar uma transformação. E a transformação
apenas diz, como faço para converter de uma imagem, um
formato PNG ou JPEG, em uma imagem que posso conectar a um modelo? Isso envolve apenas
redimensioná-lo, cortá-lo, subtrair a média
com base nas estatísticas de todo o conjunto de dados. E há muitas
outras operações que você pode fazer aqui para pré-processar. Depois de fazer essa transformação,
você pode carregar seus dados e aplicar a transformação a eles.
E esses são vários
conjuntos de dados diferentes– CIFAR 10, ImagineNet, COCO,
ObjectNet, que é um conjunto de dados que eu criei. E vou mostrar
aqui uma amostra aleatória rápida de imagens de cada um
desses conjuntos de dados para que você tenha uma noção de
como eles se parecem. Este objeto aqui também é
chamado de Data Loader, que é muito útil no
PyTorch e nos permite aprender rapidamente
lotes de dados em paralelo ao mesmo tempo. Portanto, o CIFAR 10 aqui foi
um conjunto de dados anterior. Como você pode ver, a resolução é um
pouco menor. Mas você percebe
muito rapidamente quais são as características do conjunto de dados. Por exemplo,
há muitos cachorros aqui, gatos e animais,
e os objetos estão todos centralizados e razoavelmente
grandes no campo de visão. O ImageNet foi criado
pelo Flickr, e muitas dessas imagens parecem
um pouco mais com fotos de estoque ou são feitas para serem um pouco
mais artísticas – por exemplo, esta foto de um mergulhador
segurando a criatura marinha ou um [INAUDÍVEL] .
O COCO foi criado
principalmente para fazer segmentação, mas possui cenas muito mais
desordenadas, pois possuem muitas instâncias
de objetos dentro de suas cenas. Embora tenham um
conjunto bastante restrito de objetos, eles têm uma cena muito mais
complexa para reconhecer. Então é fácil, olhando
para cada um deles, extrair o que– se
eu der a você uma imagem, você poderá me dizer de qual
conjunto de dados essa imagem veio.
Portanto, criamos este
novo conjunto de dados chamado ObjectNet, que fornece
uma variação totalmente nova em seus dados de teste,
que inclui coisas como a rotação
do objeto, o espaço que o objeto ocupava
ao ser relacionado com o próprio objeto
e o ângulo de onde você viu o objeto. E isso é muito
importante, ter cada uma dessas coisas
relacionadas a fim de realmente testar seus modelos. Porque os modelos acabam sendo
ótimos nessa tarefa do ImageNet, onde muitas imagens
têm correlações, como cadeiras de cozinha sempre
ocorrem ao lado de mesas de cozinha, ou coisas assim.
Portanto, ao relacionar
cada um deles, criamos um conjunto de dados que
parece realmente diferente. É simples, como o CIFAR
10, pois todos os objetos são centralizados na tela e grandes
e facilmente reconhecíveis por humanos. Mas ele fornece um
tipo de dificuldade diferente do COCO, pois
desrelacionamos as coisas em vez de adicionar confusão. Também incluí neste
tutorial um código de precisão de validação que você
mesmo pode experimentar. Isso é bastante simples. Ele apenas carrega os dados em lotes
usando esses diferentes carregadores de dados de conjunto de dados e, em seguida,
permite que você obtenha a precisão de 1 e 5 principais, que é
o que normalmente usamos na pesquisa de visão para basicamente
permitir que os modelos obtenham um palpite ou cinco palpites
sobre qual é a resposta correta do que está na imagem. Vou pular aqui para os
resultados reais do computador, que está comparando o
conjunto de dados ImageNet e o ObjectNet, o conjunto de dados que criei. E o que descobrimos ao
construir isso e testar nossos modelos é que há
uma grande queda absoluta de desempenho que ocorre
quando você realmente controla vários
parâmetros difíceis, como rotação e ponto de vista.

E essa grande lacuna de desempenho
mostra que nossos modelos ainda têm um longo caminho a percorrer para
atingir um desempenho de nível humano. Então, Colin vai
falar um pouco mais sobre como podemos comparar esses
modelos quando eles estão olhando para as imagens do
cérebro do rato, talvez na esperança de ser capaz de
preencher essa lacuna e construir mais
seres humanos biológicos, ou pelo menos no nível do mouse redes neurais. COLIN CORNWELL: Então, se você
quiser acompanhar este tutorial, há um hiperlink muito simples que
você pode acessar aqui – bit.ly/neuralcheese, que o
levará a um notebook do Google Colab chamado Deep Mouse Trap.
Então, a primeira coisa que
faremos aqui é
carregar algumas ferramentas que criamos para facilitar esse
processo de comparação neural do GitHub. Então, vamos executar esta célula primeiro. Se você não estiver
familiarizado com o Google Colab, observe que há uma
estrutura de diretório aqui. Então é isso que
vamos criar. Estaremos criando um
diretório, no qual iremos alterar o diretório,
para que tenhamos todas as nossas ferramentas disponíveis para nós.
Até agora falamos
sobre redes neurais profundas, como construí-las
e como testá-las. E uma maneira de testá-
los é realmente ver como eles se saem nas tarefas para as quais
foram designados. Mas também podemos
testá-los vendo quão bem esses
modelos de inspiração biológica podem realmente prever a biologia. O que
veremos hoje é o que chamamos de
conjunto de dados de neurofisiologia. Portanto, este é um
conjunto de dados que consiste em gravações elétricas e
ópticas de um cérebro animal real
, neste caso, o córtex visual do roedor. E veremos como
podemos usar as representações e o conhecimento aprendidos
pelas redes neurais para realmente prever o que está
acontecendo no cérebro e explicá-lo até certo ponto.
E, simultaneamente,
ao fazer isso, podemos pensar em como
poderíamos construir a próxima geração de modelos que poderiam prever
o cérebro e, ao fazê-lo, modelos que também funcionariam
melhor em tarefas do mundo real. Então, vamos seguir em frente
e carregar alguns recursos aqui. A primeira coisa
que obviamente queremos fazer com qualquer
tipo de comparação com o cérebro biológico real
é obter alguns dados biológicos.
Essa é a primeira coisa
que faremos aqui. Os arquivos que
carregaremos são dois arquivos, um que contém
um monte de metadados para cada um dos
neurônios reais que estamos registrando no
cérebro real do mouse, e também as respostas reais
desses neurônios. Temos algumas informações
sobre onde esses neurônios estão localizados, o que esses
neurônios fazem e também como eles responderam a um
conjunto de imagens naturais, que veremos em um segundo. Então, a primeira coisa
que temos é a informação sobre o neurônio. Algumas coisas a serem observadas
aqui, algumas informações importantes que precisamos sobre o
neurônio é de onde ele veio. Assim, por exemplo,
existem diferentes partes do córtex visual do roedor. Todos vocês provavelmente já ouviram falar
do córtex visual primário no
cérebro dos mamíferos, então essa é a primeira parte do neocórtex,
para onde a informação visual flui depois de atingir os olhos. E isso também é
recapitulado no que é chamado de córtex visual primário
no cérebro do camundongo.
Então, mais uma vez, temos
alguma profundidade de imagem. Então, isso nos diz
de onde, basicamente, em termos de
profundidade cortical real, o neurônio está
sendo amostrado, e informações sobre
a área também. Há um monte
de metadados aqui, se você estiver
interessado, há mais algumas informações
do Allen Brain Observatory de onde
este conjunto de dados veio, sobre essas variáveis de metadados. Então, depois de obtermos nossos
dados abrangentes sobre cada
neurônio individual, também precisamos examinar as
matrizes de resposta neural. Nesse caso,
carregaremos um quadro de dados que é,
em termos de dimensão, o número de neurônios por 119. Agora, a que essas 119
colunas respondem? Enquanto elas correspondem
à resposta média de cada um dos neurônios em nosso
conjunto de dados, também as 119 imagens em nosso conjunto de estímulos,
que carregarei agora. Como são essas imagens? Bem, existem
cerca de 119 imagens que são imagens em tons de cinza de
várias cenas naturais, às vezes contendo animais,
às vezes não contendo animais. Então, carregamos nossos
dados fisiológicos neurais.
E agora a questão é: como
podemos tentar usar esses dados ou prever as respostas
dos neurônios nesses dados com redes neurais profundas? A primeira coisa que
devemos fazer para facilitar esse
processo é realmente extrair da rede
as representações dessas imagens em
nosso conjunto de estímulos. Portanto, este é um processo chamado
extração profunda de recursos ou apenas extração de recursos. E o que
vamos fazer aqui é
importar algumas ferramentas. E primeiro,
vamos escolher um modelo para usar como nosso
modelo básico de recursos. Portanto, temos várias opções aqui. Temos muitos
modelos de reconhecimento de objetos, incluindo AlexNet
[? retreinado ?] no ImageNet.
Também temos alguns
modelos inicializados aleatoriamente, portanto, alguns modelos que
são totalmente construídos, mas nunca aprenderam nada. Temos vários
outros modelos que fazem coisas como
detecção e segmentação de objetos. E também incluímos
neste conjunto de dados algo chamado modelos de taxonomia, que são a
mesma arquitetura de modelos, mas treinados em diferentes
tarefas de visão computacional. E em um
contexto empírico ou científico, isso é valioso
porque, em muitos casos, queremos observar a
diferença entre o que as diferenças na
arquitetura do modelo fazem e o que as diferenças
no treinamento do modelo fazem.
E podemos fazer isso usando
os modelos de taxonomia. Portanto, para os propósitos de hoje
, usaremos o ResNet-18 ImageNet. Como estamos usando
um modelo ImageNet e porque
temos um array NumPy, como base de
nosso conjunto de estímulos, vamos usar
transformações de imagem que basicamente transformam nossos dados em
um conjunto de dados apropriado para um modelo ImageNet
de um Matriz NumPy. E vamos basicamente
extrair algumas informações desse modelo, incluindo
um comando que podemos passar para o interpretador Python
para nos fornecer nosso modelo ResNet-18 pré-treinado.
E então carregaremos
esse modelo de acordo. Se você estiver operando
em uma GPU, isso colocará o modelo na GPU. Se você não estiver
operando em uma GPU, isso não colocará
o modelo na GPU. Portanto, para passar nosso conjunto de estímulos
para nossa rede neural, primeiro precisamos criar uma
variável PyTorch a partir dele. E fazemos isso
primeiro transformando cada uma das imagens
em nosso conjunto de estímulos de acordo com as
transformações de imagem que carregamos acima. E então
os colocamos em uma matriz e os disponibilizamos em um
PyTorch.
Em seguida, passamos para a
rede neural por meio dessa função de mapeamento de recursos. E todas essas funções
que foram definidas aqui, você pode encontrar aqui
no repositório do GitHub. Então, por exemplo, agora, estamos
tentando extrair recursos. Portanto, há um arquivo Python que
mostra as operações– opa– por trás da extração de recursos. Isso pode demorar um pouco. É um pouco
caro computacionalmente fazer isso. E a principal
ferramenta PyTorch que nos permite olhar para o interior
de uma rede neural é algo chamado gancho. O que um gancho faz é
basicamente uma pequena chave que podemos usar para
abrir a caixa preta da rede neural e ver o
que está acontecendo lá dentro.
E o que está acontecendo
dentro de uma rede neural a qualquer momento
é obviamente um monte de multiplicações de matrizes. Portanto, o que obtemos de um
processo de extração de recursos é uma matriz. E, neste caso,
idealmente, o que você deseja que seja retornado a você para um
cenário do tipo comparação neural é uma matriz na qual você tem,
na primeira dimensão, quantas imagens estiverem em
seu conjunto de estímulos e, na segunda dimensão,
as ativações reais , as ativações niveladas de
qualquer camada de modelo que você esteja visualizando em um determinado momento. Nesse caso,
se estivermos olhando para a primeira
camada convolucional do ResNet-18, temos 119 imagens. E temos, para cada imagem
temos 800.000 ativações. Agora, o que isso deve
deixar imediatamente claro é que este é um
processo computacionalmente abrangente. E o que queremos
fazer, para fins
desta demonstração, mas também para
fins de análise, é reduzir
um pouco mais esses dados.
Então, para este
tutorial, vamos basicamente subconjunto deste
dicionário de mapas de recursos que temos, cada
terceira camada convolucional do ResNet-18, o que
nos dará um total de cerca de seis camadas convolucionais. E embora não tenhamos muito
tempo para entrar em detalhes hoje, o que
precisamos fazer antes de tentar qualquer tipo de
modelagem com esses recursos é reduzir
suas dimensões. Nesse caso,
usaremos uma
técnica de redução de dimensionalidade chamada projeção aleatória esparsa. Não vamos nos preocupar
muito com isso para os propósitos
da demonstração de hoje porque não
temos muito tempo. Mas você pode, é claro,
encontrar o processo aqui no
arquivo Python de extração SRP. Portanto, esse processo de extração de recursos
levará um momento. E enquanto esse
processo de extração de recursos está ocorrendo, começarei a
falar sobre a próxima seção aqui, porque estamos um
pouco pressionados pelo tempo.
Assim que tivermos nossos mapas de
recursos reduzidos de dimensionalidade , o que vamos
querer fazer é
usar esses mapas de recursos em um cenário de regressão. Então, vamos
tentar prever as representações reais
no cérebro usando agora as representações
de nossa rede neural. Observe agora que,
uma vez que reduzi a dimensionalidade
de meus mapas de recursos – na verdade, vou mostrar
isso in vivo – agora temos uma
matriz muito mais gerenciável, que é de 119 observações,
portanto, 119 estímulos, por 4.096
projeções aleatórias esparsas das
800.000 ativações originais da primeira
camada convolucional. Então, com nossas características
agora reduzidas, vamos tentar prever
algumas respostas fisiológicas reais . Mais uma vez, porque este
é um processo computacionalmente caro , temos
muitos neurônios e
muitas ativações, vamos subconjunto de nossos
6.000 ou mais neurônios originais para um conjunto de dados menor
de cerca de 500 neurônios. Na verdade, para fazer
essa corrida ainda mais rápida, vamos usar 250 neurônios. Agora vamos
basicamente passar isso para uma regressão,
onde, como nosso y ou nosso resultado previsto,
temos as 119 respostas do cérebro, 119 respostas, como nas 119
respostas médias a 119 estímulos.
E como nossos preditores,
temos as ativações de recursos reduzidos de dimensionalidade 4.096 para
essas imagens da rede profunda. Então, vamos passá-los
para uma regressão de crista. E vamos
deixar isso computar. Agora, enquanto isso
computa, darei apenas uma pequena
intuição sobre os tipos de informação
que podemos extrair fazendo esse tipo de coisa. Então, quando você faz um formato analítico de
dados em grande escala ,
no qual você pode passar muitos modelos
para essas funções e obter seu poder preditivo
do cérebro deles, você pode começar a construir
hierarquias de modelos que informam um
pouco sobre os recursos de design que você pode
querer incorporar em novas redes neurais
para prever melhor o cérebro.
Então, uma coisa que
sai disso, se olharmos para alguns
resultados reais que calculamos
nos últimos meses, uma das primeiras coisas
que vemos é que, redes neurais que se saem
melhor na precisão do ImageNet – então aqui no eixo x
aqui, você tem a precisão 1 superior para ImageNet,
e no eixo y você tem uma
pontuação R quadrada normalizada, então isso é sobre o quão bem
uma determinada rede neural faz para prever o cérebro, pelo
menos dentro de um determinado intervalo. E você vê que, à medida que as
redes neurais melhoram na classificação de objetos,
elas também melhoram na classificação do cérebro,
ou na previsão do cérebro, neste caso.
Agora, o que mais vemos? Vemos que redes neurais mais profundas –
então no eixo x aqui,
temos o número de camadas na rede neural. No eixo y, temos
as mesmas pontuações de R ao quadrado. Podemos ver que, à medida que
aumentamos o número de camadas em nossa rede, também podemos
prever melhor o cérebro, geralmente com as
camadas posteriores da rede. Isso também é verdade para o número
de feições em qualquer camada. Portanto, se uma rede neural
estiver saturada com camadas convolucionais e
tiver mais recursos correspondentes, também obteremos mais
poder preditivo para o cérebro
dessa rede. Então, esses são os
tipos de intuições que você pode obter
de um cenário analítico de dados em grande escala ,
no qual você está passando muitos modelos para
uma função que informa o quão bem eles estão
prevendo o cérebro.
Portanto, nossa função aqui foi executada. Agora realizamos uma espécie de
regressão neural preliminar, como se pode chamar. Ele salvou vários de nossos resultados
em uma pasta de saída aqui, como você pode ver. Portanto, temos vários
CSVs que são os CSVs associados a
cada camada do ResNet que calculamos. Podemos carregá-los de volta. E agora podemos basicamente
analisar nossos resultados pela área neural da qual
extraímos cada um de nossos neurônios . E podemos ver quão bem,
em geral, nossos modelos estão prevendo esses
neurônios em todo o cérebro. E com isso vou
concluir, porque acredito que estamos sem tempo.
Mas estamos felizes,
nós três… Andrei, David e
eu estamos felizes em responder a qualquer pergunta que você possa ter. E esperamos que você use este
kit de ferramentas e parte do código que
disponibilizamos hoje para fazer sua própria pesquisa
na escola de verão ou em vários exploits
futuros. Portanto, sinta-se à vontade para
visitar este repositório do GitHub e também para usar este
tutorial do Colab no futuro. APRESENTADOR: Ótimo,
muito obrigado a todos. Nós temos algumas
perguntas. A primeira de
Manuel [INAUDÍVEL].. É uma pergunta para David Mayo. Você pode falar mais
sobre como criar um novo conjunto de dados? Você mesmo tirou as
fotos? Quais são alguns dos
detalhes ou dicas operacionais interessantes? DAVID MAYO: Olá, Manuel. Sim, desculpe, não consegui
cobrir muito isso. Então todo esse projeto
foi chamado de ObjectNet. E o conjunto de dados foi capturado
usando uma plataforma que construí, onde os funcionários do Mechanical Turk
realmente usaram seus smartphones. E nós os orientamos
nesse processo de capturar uma imagem de acordo
com um rótulo que queríamos. Então criamos um rótulo,
como capturar a imagem de uma cadeira de cabeça para baixo em seu
quarto de cima.
E então o
smartphone, basicamente, tem um aplicativo da web que orienta
você no processo com uma sobreposição, onde
você deve girar o telefone no ângulo correto
e estar no lugar certo. E há um monte
de verificações diferentes. E então você
captura esta foto e a carrega de volta para nós. Portanto, este projeto tinha
cerca de 6.000 pessoas em casa tirando fotos de
objetos aleatórios em suas casas. Se estiver interessado,
confira objectnet.dev. Acho que
também está nos slides de Andrei e no meu caderno
para mais informações. APRESENTADOR: Ótimo, obrigado. O próximo é de
Sasha [INAUDÍVEL].. A que propósito a
convolução poderia servir além da detecção de borda? ANDREI BARBU: Bem,
acho que vou falar sobre isso. É qualquer operação que
você gostaria de aplicar. Então, as pessoas, por exemplo,
usam as convoluções dentro dos reconhecedores de fala
para processar sinais. Você pode ter
convoluções 2D ou 3D se quiser, digamos, encontrar
regiões em vez de apenas encontrar arestas.
Mas, no final das contas, é
apenas uma função arbitrária que você
calcula que permite aplicar essa
função a algum sinal, seja um sinal 1D,
sinal 2D, sinal 3D. Se você olhar dentro de um
livro de processamento de imagem, verá que grande parte da tecnologia
básica de processamento de imagem é baseada
em convoluções e que sua câmera
provavelmente está executando 100 etapas diferentes ou mais
para transformar uma imagem que tirou dos fótons
que atingiu o CCD, para algo que pareça
agradável aos seus olhos. Isso inclui tudo,
desde aumentar a nitidez da imagem, que é exatamente
o oposto de desfocá-la, até removê-la
e, digamos, tentar remover pixels ruins. Mesmo, digamos, mudar
o tom da imagem pode ser configurado para ser uma espécie de
convolução, se você quiser.
Essencialmente, quase
todas as operações que você faz no Photoshop,
no final das contas, estão sendo feitas com uma
convolução, além do fato de que você pode
apenas aprender alguma função arbitrária que pode não ser
interpretada por humanos. APRESENTADOR: Ótimo, obrigado. Temos um acompanhamento
de Sasha e Sophie. Como a pontuação da previsão é
interpretada e calculada? COLIN CORNWELL: Acho que isso
é relevante para o componente de previsão neural.
Então, acredito que
tínhamos duas perguntas. Uma era sobre o processo SRP,
o processo de projeção aleatória esparsa . E o outro era sobre a
previsão e o cálculo da pontuação. O cálculo da pontuação
é realmente muito simples neste caso. Portanto, para qualquer regressão em que
temos como resultado a matriz de resposta neural real –
neste caso, para uma célula, a
matriz de resposta é de 119 números. E estamos tentando
prever esses 119 números. E assim passamos os recursos
de nossa rede neural. Recebemos 119 previsões,
uma previsão para cada um dos números
para cada uma das respostas de nossos dados cerebrais. E basicamente
correlacionamos os valores previstos da rede neural com
os valores reais no cérebro. Nós elevamos isso ao quadrado, e isso
nos dá uma pontuação de R ao quadrado. Portanto, o cálculo da pontuação
é muito direto, sem truques ou qualquer
outra coisa envolvida. Agora, para as
projeções aleatórias esparsas, a
técnica de redução de dimensionalidade, isso é provavelmente
mais facilmente explicado colocando-a em contraste com a
análise de componentes principais, que é um método muito mais
popular e amplamente utilizado de
redução de dimensionalidade.
O que a análise de componentes principais
está tentando fazer é tentar encontrar uma
dimensionalidade inferior de variância, onde cada dimensão é
ortogonal às dimensões usadas anteriormente. Agora, a projeção aleatória esparsa
é um pouco diferente, pois não
procura ortogonalidade nas dimensões de variação
nas quais você está projetando. Neste caso, é
literalmente pegar projeções aleatórias,
dimensões aleatórias, e projetar os dados
nessas dimensões aleatórias, em oposição às
dimensões ortogonais. Esses são os principais, eu
diria, princípios disso, da projeção aleatória esparsa
que estamos usando para redução de dimensionalidade.
E a razão pela qual
usamos isso, na verdade, é que, de um modo geral, a análise de
componentes principais é
computacionalmente muito cara para executar em ativações
de redes profundas, especialmente algumas das maiores,
ou eu diria redes profundas mais amplas, como VG 16 , em
que os recursos da primeira
camada convolucional podem chegar aos milhões. Assim, a projeção aleatória esparsa
é uma forma de tornar mais
viável o processo de redução de dimensionalidade em
cenários de comparação neural. APRESENTADOR: Ótimo, obrigado, Colin. Temos uma pergunta de
[INAUDÍVEL] dirigida a você também. Você pode esclarecer o que
quis dizer com prever o cérebro? Quais são as entradas e saídas? COLIN CORNWELL: Sim,
OK, bem, isso é um– sim, eu
provavelmente deveria ter esclarecido isso no começo. O cérebro real que estamos
prevendo neste caso são as respostas neurais. Então, quando você se envolve em algum tipo
de experimento fisiológico, o que você está fazendo
é avaliar as respostas dos
neurônios biológicos no cérebro a certos estímulos físicos– neste caso, imagens.
Portanto, o mouse,
neste caso, está em um equipamento eletrofisiológico ou
fisiológico óptico, basicamente significando que estamos
escaneando seu cérebro ou basicamente
colocando eletrodos em seu cérebro e
registrando as respostas dessa maneira. E o que estamos fazendo
é vendo quando o mouse está olhando
para uma certa imagem, como os neurônios em
seu cérebro estão respondendo? E o que isso nos dá,
basicamente, para cada imagem, nos dá um número. Então, por exemplo, este neurônio,
com o ID de espécime de célula de 0119, para a primeira
imagem tem, neste caso– agora, as unidades específicas aqui
requerem um tutorial muito mais complicado .
Mas a unidade específica neste
caso é chamada de DF sobre F, ou a mudança na
fluorescência do neurônio. Basicamente, é
observar o brilho daquele neurônio sob uma
certa luz geneticamente modificada em resposta
a esse estímulo. E temos a mesma
assinatura para todos os estímulos em nosso conjunto de estímulos
e para todos os neurônios dos quais registramos. Então, quando digo prever
o cérebro, o que quero dizer é que, na verdade, estamos tentando,
para um determinado neurônio individual, prever esses
119 valores, usando as respostas
da rede neural a essas mesmas 119 imagens. Isso esclarece? APRESENTADOR: Espero que sim. Caso contrário, [INAUDÍVEL],
continue com outra pergunta. Nosso próximo é de
Dev [INAUDÍVEL].
Seria razoável esperar
resultados significativamente melhores? COLIN CORNWELL: Desculpe,
você poderia esclarecer o que é um SNN? Não tenho certeza, na verdade. APRESENTADOR: Dev, se você
pudesse acompanhar isso? COLIN CORNWELL:
Rede neural esparsa, presumo? APRESENTADOR: Ele está dizendo uma
rede neural com picos. COLIN CORNWELL: Sim, esta
é uma pergunta ativa. E isso depende, eu
acho, fundamentalmente de como você está modelando os dados. Portanto, os dados que
mostrei hoje são uma espécie de abstração
dos dados fisiológicos reais, no sentido de que essa é a
atividade média de um neurônio.
E quando você está
trabalhando com algo como fisiologia óptica
ou fisiologia elétrica, você realmente tem os picos
disponíveis no conjunto de dados. Então, minha suposição
seria que, se você está realmente tentando modelar os
picos individuais em um determinado neurônio, uma rede
que realmente incorpore em seu design, em suas
respostas, algum tipo de cenário de pico, se sairia um pouco melhor. Até agora, houve algumas
tentativas de usar redes neurais
para realmente modelar o cérebro. Agora, o problema é,
de um modo geral, que as redes neurais com picos
estão tendo problemas para decolar, em
termos das tarefas do mundo real que esperamos que uma
rede neural possa fazer.
E quando vemos algo,
como neste cenário, os modelos precisos do ImageNet estão
fazendo muito melhor em prever o cérebro, o ideal
seria que você também tivesse uma rede neural de pico
que pode executar simultaneamente uma tarefa do mundo real,
como reconhecimento de objetos, e também prever o cérebro. E imagino que se você
tivesse uma rede neural de alto desempenho, ela
faria um trabalho muito melhor em prever os
perfis de resposta individual dos neurônios do que uma dessas
redes convolucionais, que é muito mais uma abstração dos
processos biológicos reais acontecendo . APRESENTADOR: Ótimo, obrigado. A próxima é do
Miguel [INAUDÍVEL]. Como você sabe quais
camadas da ANN selecionam para comparar com a resposta
neural biológica real , com base no
tipo de computação esperada em uma determinada
camada biológica comparada com uma camada da ANN? COLIN CORNWELL: Então eu
acho que isso é mais uma
questão empírica, pessoalmente para mim, do que uma
questão teórica.
Portanto, neste cenário,
não está claro exatamente como os vários
cálculos diferentes em uma rede neural realmente
mapeiam os cálculos que o cérebro está realizando. Por exemplo, você amostra
de uma camada convolucional ou amostra
da camada ReLU que normalmente
sucede imediatamente a uma camada convolucional? Agora, o cérebro está fazendo
alguma limiarização não linear. Isso parece estar claro. Mas não está exatamente
claro onde está acontecendo e exatamente como está acontecendo. Portanto, se as convoluções limiares pré-não lineares
são melhores do que as convoluções limiares pós-
não lineares é, penso eu,
uma questão empírica.
O que fizemos em um
trabalho como este é que tentamos descobrir
quais camadas, em geral, estão se saindo melhor em
prever o cérebro, onde essas camadas estão na
profundidade geral da rede. Mas eu diria que,
teoricamente, provavelmente há uma resposta para
isso, mas não a tenho. E, portanto, isso
me incentiva a tentar uma abordagem mais empírica
para responder a essa pergunta. Mas certamente
ainda é uma questão em aberto. Andrei e David, se quiserem
entrar, fiquem à vontade. ANDREI BARBU: Sim,
acho que essa é uma das questões interessantes. Nossas redes não se parecem
muito com o cérebro. Redes que fazem
detecção de objetos com 500 camadas não são muito
parecidas com qualquer pedaço de córtex que alguém tenha. E então eu acho que, além
de não saber se você quer fazer onde
está a camada ReLu ou algo assim, há
a questão de quantas camadas você
precisa da sua rede para poder
explicar algo sobre um único camada em
um cérebro de rato real? Mas, separadamente, há
uma abordagem diferente que você pode adotar e
ser mais agnóstico quanto a isso, e apenas tentar comparar a
ativação em uma rede inteira com a ativação que você
registrou com o mouse e, em seguida, tentar perguntar qual
subconjunto dessa rede pode explicar melhor
o que está acontecendo? E tente
reduzir sua rede até ficar com
algo que explique ao máximo seus dados neurais.
Isso também é algo que
estávamos tentando fazer em nosso jornal. E, certamente, não somos os
únicos a tentar fazer isso. APRESENTADOR: Ótimo, obrigado. A próxima pergunta
é de [INAUDÍVEL].. São duas partes. Então, basicamente, você está usando
a arquitetura convolucional para extrair recursos relevantes
dos dados cerebrais de entrada. Então, você está usando o
peso padrão do treinamento ImageNet? Se sim, então é
realmente extensível? E também, se você
tiver 119 classes, já tentou
usar técnicas normais de aprendizado de máquina, como
Random Forest ou XGBoost? O desempenho deles é comparável? ANDREI BARBU: Só
para esclarecer, não usamos as
redes neurais para extrair recursos do cérebro. As redes são treinadas
para fazer detecção de objetos. E eles aprendem a extrair
quaisquer características das imagens que sejam úteis para o propósito
de detecção de objetos.
Então passamos as imagens
por essas redes, registramos a ativação
dentro dessas redes. Pegamos essas
ativações e tentamos compará-las com
as ativações registradas, digamos,
no cérebro de um camundongo. E fazemos isso tentando
encontrar alguma transformação linear entre eles, bem como algumas
outras técnicas que Colin não teve tempo de explorar e
que também estão em sua planilha. É uma boa pergunta
se o ImageNet é ecologicamente válido
para um mouse ou não. Talvez a visão deles seja totalmente
diferente da nossa, e eles certamente provavelmente
não estão detectando
muitos ônibus ou aviões ou qualquer coisa assim. A acuidade visual deles também é
muito diferente da nossa. E a visão deles é desenvolvida
de forma diferente da nossa. Dito isto,
ainda podemos explicar uma grande parte do que está
acontecendo dentro de seus cérebros.
E parece que o
fator determinante é o desempenho no ImageNet,
e não pequenas mudanças que fazemos nas redes. Portanto, pode ser que, se tivéssemos
um conjunto de dados melhor e mais válido ecologicamente, poderíamos
obter maior precisão..

![Giới thiệu các kênh Marketing 0 đồng [ Bài 1] – Công cụ marketing](https://59s.com.br/wp-content/uploads/2022/12/htmlF_IMG_638b365461402-1024x576.jpg)